1.4. Создание и проецирование в память существующих DBF файлов как альтернатива сериализации данных при работе с модифицированными списками CListCtrl в виртуальном режиме на диалогах MDI приложения
Этот материал ранее был опубликован в виде статьи на http://www.codeproject.com (на английском языке) после обсуждения на форуме http://sql.ru/forum/C++/.
Здесь фактически воспроизводится итоговый материал обсуждения из того же форума:
Создание и проецирование в память существующих DBF файлов как альтернатива сериализации данных при работе с модифицированными списками CListCtrl в виртуальном режиме на диалогах MDI приложения
Июль 2009 года
Продемонстрирована возможность чтения, записи и создания стандартных DBF файлов с произвольным доступом в памяти (MMF) вместо сериализации данных типичного MFC приложения для потомков классов CListCtrl в виртуальном режиме.
Загрузить демонстрационный файл с www.codeproject.com (требуется регистрация (бесплатная) на этом сайте):
ModifiedListCtrl04.zip - 121.3 Kb
Загрузить демонстрационные файлы с sql.ru (сначала просто зайдите на этот сайт, затем воспользуйтесь ссылкой):
ModifiedListCtrl04.zip – 73.0 Kb
ModifiedListCtrl04_demo.zip – 43.0 Kb
Загрузить тот же файл отсюда (переименуйте расширение в zip):
ModifiedListCtrl.004 - 121.2 Kb
Введение
Наконец-то мы можем поставить себе задачу сохранения и считывания нужной информации для нашего приложения из файлов данных. В типичном MFC приложении обычно используется стандартная сериализация данных поддерживаемая классами CDocument. В принципе ничто не мешает нам использовать этот метод для наших целей. Однако, сразу встает вопрос в каком формате хранить данные? Конечно мы можем изобрести свой собственный формат данных, присвоить ему наше расширение, например, *.eee и работать с ним так как будет удобно нам. Пожалуй, для учебных целей или там где принцип сериализации данных имеет существенное значение, этот метод весьма неплох. Но, поскольку мы проектируем рабочее приложение в котором необходимо будет иметь произвольный доступ к файловой памяти, то для нас использование сериализации уже не кажется достаточно оптимальным решением. Кроме того, для разработки собственного формата данных нужны очень веские основания. Я думаю, что удовлетворение собственного эго это не основание  .
.
Итак, во-первых, мы должны определиться с существующим форматом данных, а во-вторых, определить способ произвольного доступа к файловым данным. При такой постановке, решение этих задач вполне очевидно. Простейшим и хорошо известным форматом данных является структура dbf файла, который зарекомендовал себя вполне достойным. А произвольный доступ к содержимому файлов данных легко осуществить воспользовавшись преимуществами технологии проецирования файлов в память (memory mapped files – MMF). Главное достоинство этой технологии в том, что мы работаем с файлами как с обычной памятью. Для файлов баз данных это отличное решение. Нет необходимости предварительно считывать данные в обычную память для их дальнейшего использования, хотя мы можем делать это для небольших но часто используемых данных, с целью оптимизации, например для мета данных, описывающих структуру базы данных. Кроме того, отпадает явная необходимость заниматься буферизацией данных, что очень удобно для заполнения списков в виртуальном режиме. Также, мы можем непосредственно использовать статическую структуру базы данных для произвольного доступа к ее элементам данных. Плюс легкость использования технологии MMF. Преимуществ настолько много, что не имеет никакого смысла говорить о сериализации данных, тогда как практически при тех же усилиях мы получаем все преимущества произвольного доступа к проецируемым файлам.
Организацию работы на данном этапе мы определим таким образом. При открытии определенной табличной формы, программа ищет соответствующий ей dbf файл, описанный в наших мета данных. Если находит, то пытается открыть его и использовать его данные для заполнения соответствующего списка, в противном случае создает этот dbf файл, считывая данные из своих статических переменных. Если такой файл изменить с помощью какой-нибудь внешней программы редактирования dbf файлов, то при повторном его считывании мы увидим уже новые данные. Позже мы научимся редактировать dbf файлы непосредственно в нашей программе. Данный проект уже поставляется с готовыми файлами, расположенными в папке «Dbf». Это файлы «First.dbf», «Second.dbf» и «Third.dbf». Они имеют похожую структуру (в третьем файле поля «Name» и «Title» переставлены между собой) но по разному упорядочены. Во всех из них по 360 записей. Если мы удалим например файл «Third.dbf», то вместо него наше приложение создаст такой же файл и заполнит его данными из своих статических переменных. В результате получим пример указанный на рис. 1.
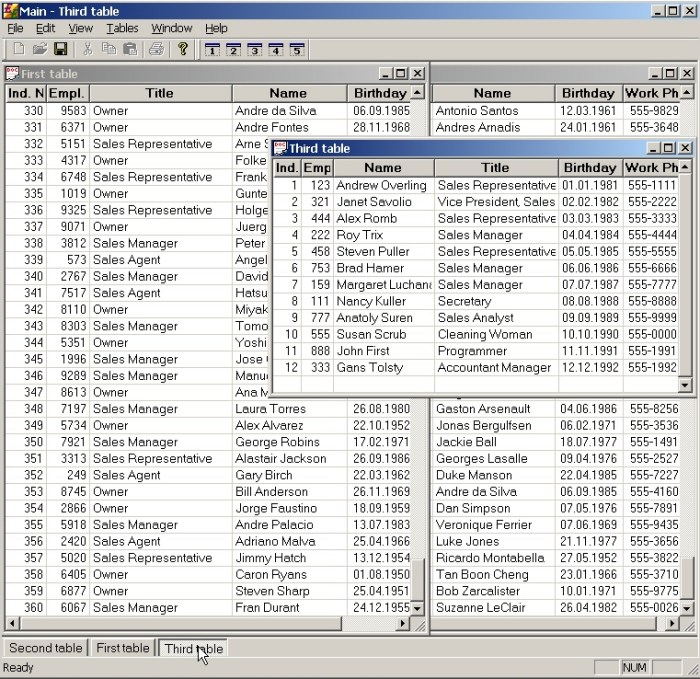
1. Структура DBF файла
В Интернете не очень трудно найти необходимую информацию про dbf файлы, поскольку этот формат открыт и давно известен. Однако официальную спецификацию найти не удалось. Поэтому мы изложим краткие результаты про их структуру (см. рис. 2).
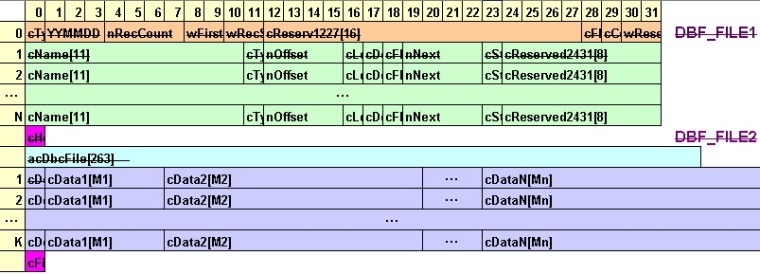
Если нам заранее известно количество полей FLDCOUNT = N в таблице данных, их длины FLDLEN1 = M1, FLDLEN2 = M2, . . . , FLDLENn = Mn и число записей RECCOUNT = K, то соответствующую структуру dbf файла можно определить как:
//*** The dbf file structure
typedef struct {
DBF_HEADER DbfHdr;
DBF_FIELD aDbfField[FLDCOUNT]; // FLDCOUNT =
// (DbfHdr.wFirstRec - 296)/32 for VFP
BYTE cHdrEnd; // Header record terminator = 0x0D (13)
BYTE acDbcFile[263]; // A data range for associated *.dbc file or
// contains 0x00
DBF_RECORD aDbfRec[RECCOUNT]; // RECCOUNT = DbfHdr.nRecCount
BYTE cFileEnd; // File record terminator = 0x1A (26)
} DBF_FILE;
где соответствующие структуры определяются как:
//*** The dbf header structure
typedef struct {
/*00-00*/ BYTE cType; // File type = 0x30 (48) for Visual FoxPro (VFP)
/*01-01*/ BYTE cYear; // Year of last update (for VFP nFullYear =
// 2000 + cYear)
/*02-02*/ BYTE cMonth; // Month of last update
/*03-03*/ BYTE cDay; // Day of last update
/*04-07*/ ULONG nRecCount; // Number of records in file
/*08-09*/ WORD wFirstRec; // Position of first data record
/*10-11*/ WORD wRecSize; // Length of one data record, including
// delete flag
/*12-27*/ BYTE cReserv1227[16]; // Reserved, contains 0x00
/*28-28*/ BYTE cFlag; // Table Flags (Only Visual FoxPro)
/*29-29*/ BYTE cCodePage; // Code page mark = 0x03 (3) for code page
// 1252 (Windows ANSI)
/*30-31*/ WORD wReserv3031; // Reserved, contains 0x00
} DBF_HEADER;
//*** The dbf field structure
typedef struct {
/*00-10*/ BYTE cName[11]; // Field name with null terminator (0x00)
/*11-11*/ BYTE cType; // Field type (C – Character; N – Numeric;
// D – Date and so on)
/*12-15*/ ULONG nOffset; // Displacement of field in record
/*16-16*/ BYTE cLen; // Length of field (in bytes)
/*17-17*/ BYTE cDec; // Number of decimal places
/*18-18*/ BYTE cFlag; // Field flag
/*19-22*/ LONG nNext; // Value of auto increment Next value
/*23-23*/ BYTE cStep; // Value of auto increment Step value
/*24-31*/ BYTE cReserv2431[8]; // Reserved, contains 0x00
} DBF_FIELD;
//*** The dbf record structure
typedef struct {
BYTE cDelete; // Delete flag
BYTE cData1[FLDLEN1]; // Where FLDLEN1 = aDbfField[0].cLen
BYTE cData2[FLDLEN2], // Where FLDLEN2 = aDbfField[1].cLen
. . .
BYTE cDataN[FLDLENN]; // Where FLDLENN = aDbfField[N-1].cLen
} DBF_RECORD;
Здесь показана статическая структура собственно dbf файлов (мы ориентируемся на формат VFP с типом файла 0x30 (48)). Для динамических структур в обычной памяти, организация данных должна быть другая – через указатели (размер которых известен) на полные структуры данных, размеры которых неизвестны на этапе компиляции программы (или не желательны для использования, чтобы не ограничивать себя конкретной структурой одного файла). А поскольку компилятор VS6 C++ не может создавать динамические типы данных, размер которых выясняется только на этапе выполнения программы (runtime), то мы не можем использовать явно описанную выше структуру данных для непосредственной манипуляции файловыми данными. Но мы также не желаем предварительно считывать данные записей в обычную память, анализировать и конвертировать их чтобы непосредственно использовать в дальнейшем. Тем самым мы теряем преимущества MMF. Таким образом, встает задача максимального описания динамических структур статическими, с целью эффективной выборки элементов данных из баз данных (в данном случае dbf файлов) на этапе выполнения программы.
2. Определение динамических структур (неизвестных размеров) с помощью статических
Эта тема достаточно важна сама по себе, чтобы уделить ей немного внимания. Обычные компиляторы не могут создавать динамические типы данных, когда размер данных определяется на этапе выполнения программы. Имеется в виду именно «тип данных», а не область памяти динамически зарезервированная под него. Проиллюстрируем сказанное известным примером. Допустим мы хотим создать массив байтов длины, которую мы определяем динамически, скажем так:
UINT nX = 100; BYTE acData[nX];
Но на эту весьма незамысловатую конструкцию компилятор «выругается». Вместо nX он хочет видеть константное выражение, вроде
BYTE acData[100];
Причем, константное выражение должно быть указано явно. Например, выражение:
UINT nCount = sizeof(aKnownStructure) / sizeof(aKnownStructure[0]); acData[nCount];
будет ошибочным, тогда как непосредственное использование:
acData[sizeof(aKnownStructure) / sizeof(aKnownStructure[0])];
будет верным.
Тем не менее, указанный массив динамически вычисляемого размера построить можно если только отказаться от явного статического определения массива и заменить его на неявное статическое определение. Т.е. вместо
BYTE acData[nX]; // Правильно, BYTE acData[100];
мы пишем
BYTE *acData = new BYTE[nX]; // UINT nX = 100;
Разница здесь в том, что в первом случае sizeof(acData) = 100, а во втором sizeof(acData) = 4. Т.е. во втором случае, на самом деле у нас не динамический тип, размером 100 байт, а статический длиной 4 байта, так как это размер указателя на динамически выделяемую область памяти размером 100 байт. С точки зрения использования данных элементов массивов – разницы никакой, а с точки зрения размеров используемых структур разница существенная. Для примера покажем еще как динамически строить двухмерный массив.
//*** Dynamic array of field names of dbf file
BYTE **aaсFldName = new BYTE *[m_nFldCount];
//*** Initializes arrays of names of dbf fields
for(int i = 0; i < m_nFldCount; i++) {
//*** Field name with a maximum of 10 characters with null terminator
m_aacFldName[i] = new BYTE[11];
//*** Copies field name
for(int j = 0; j < 11; j++)
m_aacFldName[i][j] = aDbfField[i].acName[j];
}
Это реальный код из нашего приложения. Как видно, данная техника хороша для копирования динамических структур неизвестного заранее (на этапе компиляции) размера. Но то что хорошо для часто используемых и не большого размера метаданных, не очень хорошо для огромных массивов элементов данных. Хотелось бы непосредственно обращаться к ним при их использовании (без предварительного копирования и анализа структуры). Однако для этого необходимо заранее знать ключевые параметры файла базы данных, что бы на их основе построить статические типы полных структур данных. Применительно к описанной выше структуре dbf файла, необходимо явное знание указанных там параметров. Но как уже упоминалось, даже если эти параметры для данного файла нам известны, нам не интересно указывать их программе статически, так как это ограничивает нас рассмотрением только именно этого файла. Конечно, мы можем заранее описать целое множество dbfфайлов, используемых в нашей программе, как это обычно и делается, но все равно, если мы желаем иметь доступ к произвольному dbfфайлу, то эта техника нас не устраивает.
Итак, мы подошли к противоречию. С одной стороны, статическое описание структуры базы данных (как это сделано в начале первого раздела) позволяет нам использовать преимущества проецируемых в память файлов, но ограничивает нас фиксированным набором этих структур (т.е. определенным количеством конкретных типов файлов). С другой стороны динамическое описание структур данных через указатели на структуры, неизвестных заранее размеров, приводит к необходимости использования потока входных данных неизвестной структуры, что лишает нас явных преимуществ технологии MMF, а именно произвольного доступа к элементам базы данных.
Для примера укажем, что вторым путем пошел автор «The alxBase classes for work with DBF files» by Alexey ), поэтому, техника MMF им не использовалась. Он применяет классический метод выборки данных из dbf файла путем явного позиционирования файлового указателя и затем чтения данных. Однако одно дело когда мы непосредственно пишем что-то вроде (в правой части это элементы файловой памяти):
BYTE *acDataElement = acRecord[j].acField[i]; // Примерно эквивалентно: // BYTE acDataElement[aDbfField[i].cLen];
и другое, что сначала мы должны вычислить файловый указатель текущего элемента данных, позиционироваться на него и только затем считывать данные. Но даже это не главное (для dbf файла это не сложно сделать и самому), а тот факт, что нужно заниматься еще организацией разделенного (многопользовательского, многопоточного) доступа к общим данным. Насколько я понял Alexey ограничился монопольным доступом к своей базе данных, что существенно ограничивает использование его библиотеки. Это видно уже потому, что он перестал поддерживать свой проект с 2005 года (по крайней мере, публично). В технологии MMF значительно больше возможностей для организации совместного доступа к данным, так что, я думаю, не стоит пренебрегать этой возможностью.
Но вернемся к нашему «противоречию». Ясно, что нас не устраивает ни первый, ни второй путь. Если кто-то знает третий путь, то интересно было бы узнать о нем. Мы же постараемся объединить эти способы, настолько, насколько это возможно. Отсюда следует, что раз мы не можем заранее полностью статически описать структуру dbf файла, то ограничимся тогда частичным статическим описанием, причем не одной подобной структурой, а двумя. Если мы еще раз внимательно посмотрим на приведенную выше структуру dbf файла (которую в таком виде не «поймет» компилятор), то легко видеть, что в ней можно выделить две статические части, которые уже будут «понятны» компилятору. А именно:
//*** The dbf file structure (Part No. 1)
typedef struct {
DBF_HEADER DbfHdr; // Dbf header structure
DBF_FIELD aDbfField[1]; // Really FLDCOUNT =
// (DbfHdr.wFirstRec - 296)/32 fields
} DBF_FILE1;
//*** The dbf file structure (Part No. 2)
typedef struct {
BYTE cHdrEnd; // Header record terminator = 0x0D (13)
BYTE acDbcFile[263]; // A data range for associated *.dbc file or
// contains 0x00
BYTE aDbfRec[1]; // Really DbfHdr.wRecSize * DbfHdr.nRecCount records
// BYTE cFileEnd; // File record terminator = 0x1A (26)
} DBF_FILE2;
Далее, мы воспользуемся известной «хакерской» техникой – сознательный выход за пределы статически объявленного массива данных. «Платой» за такой комбинированный подход будет переход от «плоской», «двухмерной» индексации (j, i) к «одномерной», линейной индексации ji = j*nColCount + i (для подсчета линейного номера ячейки данных) и необходимости вычисления общего линейного смещения nLineInd = j*nRowSize + m_anOff[i] (в байтах). Но, думаю, что это не слишком большая «цена», за такой подход.
Именно эти структуры мы будем реально «навешивать» на dbf файл, применяя затем сознательный выход за пределы индексов статических массивов структур aDbfField[1] и aDbfRec[1], с помощью упоминавшихся линейных индексов. Как показала практика, это вполне хороший подход и его можно использовать для других файловых данных, например, для мемо-полей (fpt файлов), индексных cdx файлов, контейнера базы данных (dbc файлов) и т.д.
3. Проецирование файлов в память (MMF) и чтение существующих dbf файлов
Чтение имеющего dbf файла происходит с помощью MMF технологии использование которой представлено в функции CMainDoc::OnOpenDocument:
/////////////////////////////////////////////////////////////////////////
// OpenDocumentFile
/////////////////////////////////////////////////////////////////////////
BOOL CMainDoc::OnOpenDocument(LPCTSTR szFileName) { // szFileName is not
// using
TCHAR *szDbfName = m_MetaTable.szDbfName;
CFileStatus FileStatus;
//*** If file szDbfName does not exist creates its
if(!CFile::GetStatus(szDbfName, FileStatus)) {
//*** Creates current document (dbf) file on physical disk
if(!CreateDocumentFile(szDbfName)) {
//_M("CMainDoc: Failed to create a document file!");
return FALSE;
}
}
//*** Gets handle of dbf file
m_hDbfFile = ::CreateFile(
szDbfName, // Name of dbf file
GENERIC_READ | GENERIC_WRITE, // Access (read-write) mode
FILE_SHARE_READ | FILE_SHARE_WRITE, // Share mode
NULL, // Pointer to security attributes
OPEN_EXISTING, // How to create
FILE_ATTRIBUTE_NORMAL, // File attributes
NULL // HANDLE hTemplateFile - Handle to file with attributes to
// copy
);
if(m_hDbfFile == INVALID_HANDLE_VALUE) {
_M("CMainDoc: Failed to call ::CreateFile function!");
return FALSE;
}
//*** The message buffer
TCHAR szStr[MAXITEMTEXT];
//*** Gets file size in bytes
ULONG nDbfSize = ::GetFileSize(
m_hDbfFile, // Handle of file to get size of
NULL // Pointer to high-order word for file size
);
//*** Checks file size
if(nDbfSize == 0) {
swprintf(
szStr,
_T("CMainDoc: File '%s' is empty!"),
szDbfName
);
_M(szStr);
::CloseHandle(m_hDbfFile);
return FALSE;
}
//*** Creates file mapping
m_hDbfMap = ::CreateFileMapping(
m_hDbfFile, // Handle to file to map
NULL, // Optional security attributes
PAGE_READWRITE, // Protection for mapping object
0, // High-order 32 bits of object size
0, // Low-order 32 bits of object size
NULL // Name of file-mapping object
);
if(!m_hDbfMap) {
_M("CMainDoc: Failed to call ::CreateFileMapping function!");
return FALSE;
}
//*** Maps view of dbf file for its first part (where are header)
m_pDbfView1 = reinterpret_cast<DBF_FILE1 *>(::MapViewOfFile(
m_hDbfMap, // File-mapping object to map into address space
FILE_MAP_WRITE, // Access mode
0, // High-order 32 bits of file offset
0, // Low-order 32 bits of file offset
0 // Number of bytes to map (if it is zero, the entire file is
// mapped)
));
if(!m_pDbfView1) {
_M("CMainDoc: Failed to call ::MapViewOfFile function!");
return FALSE;
}
//*** Dbf header structure
m_pDbfHdr = &m_pDbfView1->DbfHdr;
//*** Checks dbf file type
if(m_pDbfHdr->cType != VFPTYPE) { // = 0x30 (48)
swprintf(
szStr,
_T("CMainDoc: Dbf type: %d does not equal to VFP type: %d!"),
m_pDbfHdr->cType,
VFPTYPE
);
_M(szStr);
return FALSE;
}
//*** Shows date of last update
/*
swprintf(
szStr,
_T("Date of last update is %0.2d.%0.2d.%d"),
m_pDbfHdr->cDay,
m_pDbfHdr->cMonth,
BASEYEAR + m_pDbfHdr->cYear
);
_M(szStr);
*/
//*** Number of records in file
m_nRecCount = m_pDbfHdr->nRecCount;
//*** Length of one data record (including delete flag)
m_nRecSize = m_pDbfHdr->wRecSize;
//*** Checks record size
if((m_nRecSize == 0 && m_nRecCount != 0) ||
(m_nRecSize != 0 && m_nRecCount == 0)) {
swprintf(
szStr,
_T("CMainDoc: Not matches record size (%d) and record count
(%d)!"),
m_nRecSize,
m_nRecCount
);
_M(szStr);
return FALSE;
}
//*** Calculates size of all records
ULONG nDataSize = nDbfSize - 1 - m_pDbfHdr->wFirstRec;
//*** Checks record parameters
if(nDataSize != m_nRecCount*m_nRecSize) {
swprintf(
szStr,
_T("CMainDoc: Data size (%d) does not equal record count (%d) *
record size (%d)!"),
nDataSize,
m_nRecCount,
m_nRecSize
);
_M(szStr);
return FALSE;
}
//*** Number of fields in file (for Visual FoxPro only)
m_nFldCount = (m_pDbfHdr->wFirstRec - 296)/32;
//*** Checks field count
if(m_nFldCount > m_nRecSize - 1) {
_M("CMainDoc: Field count is very large!");
return FALSE;
}
//*** Dbf field structure
DBF_FIELD *aDbfField = m_pDbfView1->aDbfField;
//*** Maps view of dbf file for its first part (where are data)
m_pDbfView2 = reinterpret_cast<DBF_FILE2 *>(
&m_pDbfView1->aDbfField[m_nFldCount].acName[0]
);
BYTE cHdrEnd = 0;
//*** Checks dbf reading
try {
cHdrEnd = m_pDbfView2->cHdrEnd;
} catch(...) {
_M("CMainDoc: Dbf file has wrong structure!");
return FALSE;
}
//*** Checks dbf header record terminator
if(cHdrEnd != HEADEREND) { // = 0x0D (13)
swprintf(
szStr,
_T("CMainDoc: Header record terminator: %d does not equal to:
%d!"),
m_pDbfView2->cHdrEnd,
HEADEREND
);
_M(szStr);
return FALSE;
}
//*** Delete flag // = " " or "*"
//_M(pDbfFile2->aDbfRec[0]);
//*** Dynamic array of field names
m_aacFldName = new BYTE *[m_nFldCount];
//*** Dynamic array of field types
m_acFldType = new BYTE[m_nFldCount];
//*** Dynamic array of offsets
m_anOff = new UINT[m_nFldCount];
//*** Dynamic array of lengths
m_acLen = new BYTE[m_nFldCount];
//*** Dynamic array of decimal places
m_acDec = new BYTE[m_nFldCount];
//*** Initializes arrays of length, offsets and etc. of dbf fields
for(int i = 0; i < m_nFldCount; i++) {
//*** Field name with a maximum of 10 characters with null terminator
m_aacFldName[i] = new BYTE[11];
//*** Copies field name
for(int j = 0; j < 11; j++)
m_aacFldName[i][j] = aDbfField[i].acName[j];
//*** Field type
m_acFldType[i] = aDbfField[i].cType;
//*** Field lenght (in bytes)
m_acLen[i] = aDbfField[i].cLen;
//*** Number of decimal places (in bytes)
m_anOff[i] = aDbfField[i].nOffset;
//*** Number of decimal places (in bytes)
m_acDec[i] = aDbfField[i].cDec;
}
//*** Testing for all field of j-th record
/*
//*** j-th record
ULONG j = 11;
//*** Line displacement of i-th field of j-th record
ULONG ji = 0;
for(i = 0; i < m_nFldCount; i++) {
ji = j*m_nRecSize + m_anOff[i];
//*** The copy of (j, i) field value of m_anLen[i]-th length
// As it has not null terminator
CString sFldVal((LPCSTR) &m_pDbfMap2->aDbfRec[ji], m_anLen[i]);
sFldVal.TrimLeft();
sFldVal.TrimRight();
swprintf(
szStr,
_T("%s : %c : %d : %d.%d :: '%s'"),
(CString) aszFldName[i], // As it has null terminator
acFldType[i],
m_anOff[i],
m_anLen[i],
m_anDec[i],
sFldVal
);
_M(szStr);
}
*/
BYTE cFileEnd = 0;
//*** Checks dbf reading
try {
cFileEnd = m_pDbfView2->aDbfRec[m_nRecCount * m_nRecSize];
} catch(...) {
_M("CMainDoc: Dbf file has wrong structure!");
return FALSE;
}
//*** Checks dbf file record terminator
if(cFileEnd != DBFEND) { // = 0x1A (26)
swprintf(
szStr,
_T("CMainDoc: Header record terminator: %d does not equal to:
%d!"),
m_pDbfView2->aDbfRec[m_nRecCount * m_nRecSize],
DBFEND
);
_M(szStr);
return FALSE;
}
//*** Current table
CListCtrlEx *pTable = m_pMainApp->m_apTable[m_eTable];
if(!pTable) {
_M("CMainDoc: Empty a CListCtrlEx object!");
return FALSE;
}
//*** Sets the table rows count in the virtual mode (LVS_OWNERDATA)
//*** Send messages LVN_GETDISPINFOW & HDM_LAYOUT
//*** Calls the CListCtrlEx::DrawItem
pTable->SetItemCount(m_nRecCount);
//*** Shows the vertical scroll bar always
//pTable->ShowScrollBar(SB_VERT);
//*** Saves the current document
m_pMainApp->m_apDoc[m_eTable] = this;
return TRUE;
} // OnOpenDocument
4. Создание dbf файлов и заполнение их статическими данными
Чтобы создать файл базы данных, нужно предварительно знать его структуру. В нашей демонстрационной программе имеются три таких статических структуры, которые позволяют создавать три различных dbf файла. Меняя их количество и содержимое можно создавать достаточно произвольные файлы баз данных формата Visual FoxPro. Вот основные структуры метаданных:
//*** The dbf file fields data structure
typedef struct {
TCHAR *szFldName; // Field name
TCHAR *szFldType; // Field type
UINT nFldLen; // Field length (in bytes)
UINT nDecLen; // Number of decimal places (in bytes)
} META_DATA;
//*** The meta table header structure
typedef struct {
TCHAR *szHdrName; // Column name
DWORD nAdjust; // Text formatting
UINT nWidth; // Column width
} META_HEADER;
//*** The meta table structure
typedef struct {
TCHAR *szDbfName; // Dbf name
META_DATA *aMetaData; // Dbf file fields data structure
TCHAR *szTblName; // Table name
META_HEADER *apMetaHeader; // Meta table header structure
DWORD dwStyle; // Table style
DWORD dwExStyle; // Extended table style
RECT *pFrmRect; // Frame rectangle pointer
RECT *pViewRect; // View rectangle pointer
CFont *pHdrFont; // Table header font pointer
CFont *pListFont; // Table list font pointer
UINT nHdrHeight; // Table header height
UINT nListHeight; // Table list height
UINT nColCount; // Table header columns count
UINT nRowCount; // Table list row count
TCHAR **apRowText; // Table rows text array
} META_TABLE;
Используя эти структуры функция CMainDoc::CreateDocumentFile создает нужный dbf файл:
/////////////////////////////////////////////////////////////////////////
// CreateDocumentFile
/////////////////////////////////////////////////////////////////////////
BOOL CMainDoc::CreateDocumentFile(TCHAR *szDbfName) {
//*** The dbf file structure
/*
typedef struct {
DBF_HEADER DbfHdr;
DBF_FIELD aDbfField[FLDCOUNT]; // FLDCOUNT =
// (DbfHdr.wFirstRec - 296)/32 for VFP
BYTE cHdrEnd; // Header record terminator = 0x0D (13)
BYTE acDbcFile[263]; // A data range for associated *.dbc file,
// contains 0x00
DBF_RECORD aDbfRec[RECCOUNT]; // RECCOUNT = DbfHdr.nRecCount
BYTE cFileEnd; // File record terminator = 0x1A (26)
} DBF_FILE;
*/
CFileStatus FileStatus;
//*** If file szDbfName does exist simply return
if(CFile::GetStatus(szDbfName, FileStatus))
return TRUE;
//*** Number of records in file
ULONG nRecCount = m_MetaTable.nRowCount;
//*** Data table fields count
UINT nFldCount = m_MetaTable.nColCount;
SYSTEMTIME SysTime = {0};
//*** Gets system date and time
GetSystemTime(&SysTime);
//*** Dbf header structure
DBF_HEADER DbfHdr = {0};
DbfHdr.cType = VFPTYPE; // DBF type
DbfHdr.cYear = SysTime.wYear%BASEYEAR; // Year of last update
DbfHdr.cMonth = SysTime.wMonth; // Month of last update
DbfHdr.cDay = SysTime.wDay; // Day of last update
DbfHdr.nRecCount = nRecCount; // Number of records in file
//DbfHdr.wFirstRec = 0; // Position of first data record
//DbfHdr.wRecSize = 0; // Length of one data record, including delete
// flag
//DbfHdr.cFlag = 0; // Table Flags (Only Visual FoxPro)
DbfHdr.cCodePage = CP1252; // Windows ANSI
//*** Dbf field structure
DBF_FIELD DbfField = {0};
//*** Gets handle of dbf file
HANDLE hDbfFile = ::CreateFile(
szDbfName, // Pointer to name of the dbf file
GENERIC_WRITE, // Access (read-write) mode
0, // Share mode
NULL, // Pointer to security attributes
CREATE_ALWAYS, // How to create
FILE_ATTRIBUTE_NORMAL, // File attributes
NULL // HANDLE hTemplateFile - Handle to file with attributes to
// copy
);
//*** Message buffer
TCHAR szStr[MAXITEMTEXT];
//*** Checks file creation
if(hDbfFile == INVALID_HANDLE_VALUE) {
swprintf(
szStr,
_T("CMainApp: Failed to create new file: '%s'!"),
szDbfName
);
_M(szStr);
::CloseHandle(hDbfFile);
return FALSE;
}
//*** Number of written bytes
DWORD dwBytes = 0;
//*** Writes bytes into file
WriteFile(hDbfFile, &DbfHdr, sizeof(DbfHdr), &dwBytes, NULL);
//*** Dynamic array of field length
BYTE *acFldLen = new BYTE[nFldCount];
//*** Dynamic array of field types
BYTE *acFldType = new BYTE[nFldCount];
UINT nOffset = 1; // Skips delete byte
//*** Writes array of DBF_FIELD aDbfField[FLDCOUNT] structures
for(int i = 0; i < nFldCount; i++) {
META_DATA MetaData = m_MetaTable.aMetaData[i];
BYTE *acName = DbfField.acName;
TCHAR *szFldName = MetaData.szFldName;
//*** Field name with a maximum of 10 characters, a rest is padded
// with 0x00
//for(int j = 0; j < 11; j++)
//acName[j] = szFldName[j];
//*** Simply copies
while(*acName++ = *szFldName++);
acFldType[i] = MetaData.szFldType[0]; // Field type
DbfField.cType = acFldType[i]; // Field type
DbfField.nOffset = nOffset; // Displacement of field in record
acFldLen[i] = MetaData.nFldLen; // Length of field (in bytes)
DbfField.cLen = acFldLen[i]; // Length of field (in bytes)
DbfField.cDec = MetaData.nDecLen; // Number of decimal places
nOffset += acFldLen[i];
//*** Writes bytes into file
WriteFile(hDbfFile, &DbfField, sizeof(DbfField), &dwBytes, NULL);
}
//*** Length of one data record, including delete flag
DbfHdr.wRecSize = nOffset; // ARE NOT WRITTEN YET!
//*** Header record terminator
BYTE cHdrEnd = HEADEREND; // = 0x0D (13)
//*** Writes bytes into file
WriteFile(hDbfFile, &cHdrEnd, sizeof(cHdrEnd), &dwBytes, NULL);
//*** A data range for associated *.dbc file, contains 0x00
BYTE acDbcFile[263] = {0};
//*** Writes bytes into file
WriteFile(hDbfFile, &acDbcFile, sizeof(acDbcFile), &dwBytes, NULL);
//*** Gets current file pointer
DWORD nCurOffset = SetFilePointer(hDbfFile, 0, NULL, FILE_CURRENT);
//*** Position of first data record
DbfHdr.wFirstRec = nCurOffset; // ARE NOT WRITTEN YET!
//*** The delete flag
BYTE cDelete = 32; // = 0x20 (" ")
//*** Line table cell index
UINT ji = 0;
//*** Writes array of DBF_RECORD aDbfRec[RECCOUNT] structures
for(ULONG j = 0; j < nRecCount; j++) {
//*** Writes bytes into file
WriteFile(hDbfFile, &cDelete, sizeof(cDelete), &dwBytes, NULL);
//*** Writes array of BYTEs strings
for(i = 0; i < nFldCount; i++) {
ji = j*nFldCount + i; // Line table cell index
TCHAR *acRowText = m_MetaTable.apRowText[ji];
BYTE cFldLen = acFldLen[i];
BYTE cFldType = acFldType[i];
//*** Dinamic array of field data
BYTE *acFldData = new BYTE[cFldLen + 2]; // +2 for sake date format
//*** Copies field data (into BYTEs from TCHARs)
for(int k = 0; k < cFldLen; k++)
acFldData[k] = acRowText[k];
//*** Formates our date string (DD.MM.YYYY) into dbf style
// (YYYYMMDD)
if(cFldType == 68) { // = 0x44 ("D") – Date
if(cFldLen != 8) {
swprintf(
szStr,
_T("CMainApp: Length of date format is %d. Must be 8!"),
cFldLen
);
_M(szStr);
return FALSE;
}
if(cFldLen == 8) { // Date length for dbf date format
//*** Our static date has 10 characters
acFldData[8] = acRowText[8];
acFldData[9] = acRowText[9];
//*** Date format is d1d2.m1m2.y1y2y3y4 .
// Must be y1y2y3y4m1m2d1d2
acFldData[2] = acFldData[8]; // Writes y3
acFldData[5] = acFldData[4]; // Writes m2
acFldData[4] = acFldData[3]; // Writes m1
acFldData[3] = acFldData[9]; // Writes y4
acFldData[8] = acFldData[0]; // Saves d1
acFldData[9] = acFldData[1]; // Saves d2
acFldData[0] = acFldData[6]; // Writes y1
acFldData[1] = acFldData[7]; // Writes y2
acFldData[6] = acFldData[8]; // Writes d1
acFldData[7] = acFldData[9]; // Writes d2
}
//*** Else do nothing
}
//*** Writes bytes into file
WriteFile(hDbfFile, acFldData, cFldLen, &dwBytes, NULL);
}
}
//*** File record terminator
BYTE cFileEnd = DBFEND; // = 0x1A (26)
//*** Writes bytes into file
WriteFile(hDbfFile, &cFileEnd, sizeof(cFileEnd), &dwBytes, NULL);
//*** Calculates file pointer to DbfHdr.wFirstRec
ULONG nPos = (ULONG) &DbfHdr.wFirstRec - (ULONG) &DbfHdr.cType; // = 8
WORD wFirstRec = DbfHdr.wFirstRec;
WORD wRecSize = DbfHdr.wRecSize;
//*** Sets file pointer in DbfHdr.wRecSize position
SetFilePointer(hDbfFile, nPos, NULL, FILE_BEGIN);
//*** Writes NOT WRITTEN YET bytes into file
WriteFile(hDbfFile, &wFirstRec, sizeof(wFirstRec), &dwBytes, NULL);
//*** Writes next NOT WRITTEN YET bytes into file
WriteFile(hDbfFile, &wRecSize, sizeof(wRecSize), &dwBytes, NULL);
::CloseHandle(hDbfFile);
return TRUE;
} // CreateDocumentFile
5. Обработка данных в виртуальном режиме
В заключение продемонстрируем код обработчика LVN_GETDISPINFO, который «отвечает» за виртуальный режим.
/////////////////////////////////////////////////////////////////////////
// OnChildNotify
/////////////////////////////////////////////////////////////////////////
BOOL CListCtrlEx::OnChildNotify(UINT message, WPARAM wParam,
LPARAM lParam, LRESULT *presult) {
NMHDR *pNMHdr = reinterpret_cast<NMHDR *>(lParam);
LV_DISPINFO *pLVDI = reinterpret_cast<LV_DISPINFO *>(lParam);
LV_ITEM *pItem = &pLVDI->item;
if(message == WM_NOTIFY) {
switch(pNMHdr->code) {
case LVN_GETDISPINFO: {
if(pItem->mask & LVIF_TEXT) {
//*** Item row
UINT nRow = pItem->iItem;
//*** Item column
UINT nCol = pItem->iSubItem;
//*** The message buffer
TCHAR szStr[MAXITEMTEXT];
//*** Current document
m_pDoc = m_pMainApp->m_apDoc[m_eTable];
if(!m_pDoc) {
_M("CListCtrlEx::CListCtrlEx : Empty document!");
//*** Forces to exit from the application as else will be a
// lot messages
exit(-1);
}
//*** Number of fields in dbf file
ULONG nColCount = m_pDoc->m_nFldCount;
// = m_MetaTable.nColCount;
if(nColCount == 0) {
_M("CListCtrlEx::OnChildNotify : Column count = 0!");
//*** Forces to exit from the application as else will be a
// lot messages
exit(-1);
}
if(m_MetaTable.nColCount != nColCount) {
swprintf(
szStr,
_T("CListCtrlEx::OnChildNotify : Table (%d) and Dbf (%d)
columns are different!"),
m_MetaTable.nColCount,
nColCount
);
_M(szStr);
//*** Forces to exit from the application as else will be a
// lot messages
exit(-1);
}
//*** Number of records in dbf file
ULONG nRowCount = m_pDoc->m_nRecCount;
if(nRowCount == 0) {
_M("CListCtrlEx::OnChildNotify : Row count = 0!");
//*** Forces to exit from the application as else will be a
// lot messages
exit(-1);
}
//*** Sets row count into meta table
//if(m_MetaTable.nRowCount != nRowCount)
m_MetaTable.nRowCount = nRowCount;
//*** Length of one data record (including delete flag)
ULONG nRowSize = m_pDoc->m_nRecSize;
if(nRowSize == 0) {
_M("CListCtrlEx::OnChildNotify : Row size = 0!");
//*** Forces to exit from the application as else will be a
// lot messages
exit(-1);
}
//*** Line displacement of nCol-th field of nRow-th record
ULONG nLineInd = nRow*nRowSize + m_pDoc->m_anOff[nCol];
if(nLineInd < 0) {
_M("CListCtrlEx::OnChildNotify : Line index < 0!");
//*** Forces to exit from the application as else will be a
// lot messages
exit(-1);
}
//*** Maps view of dbf file for its second part (where are data)
DBF_FILE2 *m_pDbfView2 = m_pDoc->m_pDbfView2;
if(!m_pDbfView2) {
_M("CListCtrlEx::OnChildNotify : Empty view of dbf file!");
//*** Forces to exit from the application as else will be a
// lot messages
exit(-1);
}
//*** The Visual FoxPro records
BYTE *aDbfRec = m_pDbfView2->aDbfRec;
if(!aDbfRec) {
_M("CListCtrlEx::OnChildNotify : Empty records into dbf
file!");
//*** Forces to exit from the application as else will be a
// lot messages
exit(-1);
}
//*** Line table cell index
UINT ji = nRow*nColCount + nCol;
if(ji < 0) {
_M("CListCtrlEx::OnChildNotify : Line cell index < 0!");
//*** Forces to exit from the application as else will be a
// lot messages
exit(-1);
}
if(ji < nRowCount*nColCount) {
try {
//*** Copies (j, i) field value of m_anLen[i]-th length
// We do this as it has not null terminator
CString sFldVal(
(LPCSTR) &aDbfRec[nLineInd],
m_pDoc->m_acLen[nCol]
);
//*** Formates date string into German style
if(m_pDoc->m_acFldType[nCol] == 68) {
// = 0x44 ("D") – Date
CString sDate =
sFldVal.Right(2) + _T(".") +
sFldVal.Mid(4, 2) + _T(".") +
sFldVal.Left(4);
sFldVal = sDate;
}
wcscpy((wchar_t *)(pItem->pszText), sFldVal);
} catch (...) {
//*** Forces to exit from the application as else will be a
// lot messages
exit(-1);
}
} else {
wcscpy((wchar_t *)(pItem->pszText), _T("***"));
}
}
break;
}
}
}
return CListCtrl::OnChildNotify(message, wParam, lParam, presult);
} // OnChildNotify