1.5.6.2. Внешняя сортировка «естественным слиянием»
Здесь фактически воспроизводится итоговый материал обсуждения статьи: «Реализация на С++ внешней сортировки «естественным слиянием» (Natural Merge Sort)»:
Рабочий алгоритм на С++ внешней сортировки «естественным слиянием» (Natural Merge Sort) с неубывающими и убывающими упорядоченными подпоследовательностями
Январь 2010 года
Продемонстрирована возможность извлечения блока строковых данных из бинарного файла типа DBF с произвольным доступом в памяти (MMF) и сортировка этих данных в один из двух временных буферов. Использована оптимизация по скорости сортировки и объему используемой буферной памяти.
Загрузить тестовую программу отсюда (переименуйте расширение в zip):
Загрузить тестовую программу с sql.ru (сначала просто зайдите на этот сайт, затем воспользуйтесь ссылкой):
На форуме «Программирование» сайта sql.ru мною уже был опубликован похожий алгоритм в демонстрационном варианте, написанный на Visual FoxPro. Однако данный вариант, написанный на C++ более тщательно выверен на наличие ошибок, чем предыдущий и практически готов для использования в реальных приложениях. Тем не менее, предела совершенствования не существует, потому приветствуются любые конструктивные замечания и предложения.
Введение
Рано или поздно любой программист сталкивается с необходимостью явного использования того или иного метода сортировки. Не смотря на то, что эта тема хорошо исследована и существует масса прекрасных алгоритмов сортировки, при практическом их использовании возникает ряд нюансов. Во-первых, это проблема выбора. Действительно, как из хорошего выбрать лучшее, тем более что четких рекомендаций нет, мол «каждый алгоритм хорош по своему». А во-вторых, всегда существует проблема реализации применительно к практической задаче. Возможно, опыт автора в этой области может оказаться кому-то полезным, поэтому опишем наши исследования и практические результаты.
Хотя обычно конкретный алгоритм сортировки выбрать трудно, но вполне можно определиться с классом алгоритмов, зависящим от данной задачи. В моем случае, это была необходимость самостоятельной сортировки строковых данных из заданного столбца табличной базы данных (конкретно dbf файла) во внешний файловый буфер. Т.е. сортировка по определению должна быть внешней так как исходный файл мог быть достаточно большим (порядка гигабайта) и кроме того сортировка может быть осуществлена для нескольких столбцов одновременно. Цель сортировки – создание индексного файла для одного или нескольких полей данных. Мы здесь не будем обсуждать нужно или не нужно делать подобную сортировку самим, когда существуют множество программных продуктов, особенно ориентированных на работу с базами данных, и уже делающих подобную работу достаточно хорошо. Бывают случаи, когда не хочется без крайней необходимости привлекать внешние программы для не очень сложных собственных программ. Поэтому попытаемся решать данную задачу в указанной постановке.
Итак, мы определились, что нас интересует алгоритм внешней сортировки. Поскольку мы не собираемся модифицировать источник данных, то для сортировки одного столбца данных нам может понадобится два файловых буфера размером равным произведению количества исходных данных на длину поля данных. Реально нас еще будет интересовать номер записи каждой строки поля данных (для целей индексации). Поскольку размер длинного целого в Win32 равен 32 битам или 4 байтам, то длину поля в байтах нам нужно будет увеличить еще на 4 байта.
Известно, что для общей сортировки нескольких длинных упорядоченных подпоследовательностей удобен метод слияния (Merge Sort) который из очередей данных последовательно выбирает максимальное или минимальное значение и записывает его в искомую последовательность. Если же исходные данные не представлены в виде нескольких Упорядоченных ПодПоследовательностей (Ordered SubSequences ), которые мы также будем называть УПП (OSS), то такие УПП нужно будет получить, т.е. расщепить (Split) тем или иным способом. Например, отсортировав относительно небольшую последовательность случайных данных в памяти любым удобным для этих целей алгоритмом, например, алгоритмом быстрой сортировки. Понятно, что вместо слияния или объединения (Merge) нескольких УПП можно ограничиться их попарным слиянием до тех пор, когда не останется одна единственная (искомая) УПП.
Очевидно, что вариантов функций Split может быть множество и действительно информации на эту тему опубликовано достаточно. Причем внешняя сортировка не ограничивается только методом слияния (Merge Sort), однако мы не будем рассматривать другие методы, так как нас вполне устраивает рассматриваемый здесь базовый класс алгоритмов внешней сортировки.
Итак, нам нужно определиться с выбором функции Split и количеством одновременно используемых УПП для функции Merge. Второй вопрос решается легко, мы просто выберем метод попарного объединения, так как он очень удобен для реализации. Осталось определиться со Split.
Функция Split может либо сортировать в памяти относительно небольшие подпоследовательности данных либо каким-то образом извлекать УПП из заданной последовательности. Мы сразу отказываемся от дополнительной сортировки в памяти, во-первых, это усложняет общий алгоритм, а во-вторых, что более существенно, не используются уже существующие упорядоченные подпоследовательности (УПП). Логично назвать способы извлечения этих естественным образом уже упорядоченных подпоследовательностей из заданной последовательности данных –
1. Исходная последовательность данных рассматривается как множество УПП длины 1, которые упорядочены по определению. Две УПП длины 1 сливаются в одну длины 2, во второй буфер, "двойки" в "четверки" в первый буфер (или в исходный файл, если допустимо его изменение) и так попеременно (http://iproc.ru/parallel-programming/lection-6/).
2. Исходная последовательность данных расщепляется на последовательные серии, т.е. неубывающие УПП. При слиянии сначала выполняется распределение серий исходного файла A попеременно по временным файлам B и C, а потом слияние B и C в файл A и т.д. пока не останется одна серия (http://www.citforum.ru/programming/theory/sorting/sorting1.shtml).
3. Исходная последовательность данных расщепляется на серии одновременно с начала и конца, причем эти серии сразу же объединяются в первый буфер попеременно в его начало (в прямом порядке) и конец (в обратном порядке). Затем данный буфер становится источником данных и результат выводится во второй буфер (или в исходный файл, если допустимо его изменение). Затем второй и первый буфера меняются местами и т.д. Этот алгоритм носит название естественного двухпутевого слияния (http://inf.1september.ru/2000/9/art/10a.htm).
Очевидные недостатки этих «естественных расщеплений и слияний» это то, что первый случай не учитывает уже существующий порядок данных, а второй и третий не учитывают убывающие УПП. Кроме того, во втором случае фактически используются три буфера, если мы зададимся условием не изменять исходные данные, тогда как легко можно обойтись двумя, как в первом и третьем случаях.
Нам не встречался в литературе описанный ниже четвертый вариант «естественного расщепления и слияния» исходных данных, хотя это не означает, что он еще не известен. В данном случае оказалось легче «переоткрыть» этот вариант, чем найти его.
4. Исходная последовательность файловых данных расщепляется (Split) на УПП произвольного порядка (как неубывающих, так и убывающих). Затем все УПП попарно (для всевозможных пар, в том числе вновь созданных) объединяются (Merge) в соответствующий файловый буфер, на соответствующее место.
Чтобы делать подобное расщепление (Split) лишь один раз и не отводить под структуры данных функции Split массив данных пропорциональный размеру исходного файла, мы будем сразу же использовать эти данные. В этом случае нам понадобится дополнительный массив структур фиксированного размера, для Win32 максимальная размерность массива будет равна 32. Неубывающие УПП объединяются с начала, а убывающие с конца в любой свободный файловый буфер. Если одна УПП находится в первом буфере, а вторая во втором, то перед их слиянием УПП из первого буфера просто копируется во второй, а затем две УПП второго буфера сливаются в первый буфер в соответствующие позиции. Очевидно, что достаточно всего двух буферов, а если мы не хотим делать операции копирования, то трех. Однако мы предпочтем перенос блока данных третьему буферу, ради экономии дискового пространства.
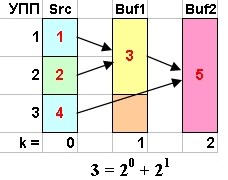
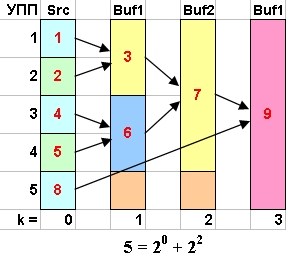
Реализация этого алгоритма довольна сложна и существенным образом зависит от двоичного разложения числа упорядоченных подпоследовательностей. Сам алгоритм распадается на две части. Первая часть делает четные (всевозможные попарные) объединения, а вторая объединяет нечетные ("зависшие") УПП. Информация о "нечетных" УПП будет храниться в упомянутом выше массиве структур размерностью 32. Нас будут интересовать те элементы этого массива, индексы которого совпадают со степенями двоичного разложения данного числа УПП. Естественно, что если количество всех исходных УПП является степенью двойки, то вторая часть алгоритма нам не понадобится. Для подробной иллюстрации алгоритма мы будем использовать множество рисунков.
Преимущество указанного алгоритма в том, что он использует по максимуму существующий частичный порядок данных. И даже в случае абсолютно равномерно распределенной случайной последовательности данных их средняя длина УПП L > 2, так как любые две сравнимые величины всегда образуют УПП. Хотя возможен частный случай «зигзагообразной» последовательности данных произвольной длины, средняя длина L УПП которой в точности равна двум. Например, для последовательности нулей и единиц:
Фактически эта последовательность обладает минимальным порядком для целей нашего алгоритма. Однако нашим преимуществом остается один проход для функции Split, фиксированный объем данных для ее параметров и наличие только двух файловых буферов (с учетом неизменности исходных данных).
Но вернемся к случаю равномерно распределенной случайной последовательности данных. Какова будет средняя длина L (определяемая как отношение суммарной длины последовательности к количеству всех УПП на ней)? Ясно, что в этом случае
и тем самым мы можем использовать этот дополнительный порядок для более быстрой сортировки. А это можно сказать уже алгоритмическое преимущество.
Задача по вычислению средней длины УПП L для равномерно распределенной случайной последовательности данных не кажется очень сложной, однако в Интернете не удалось найти готовое решение, поэтому пришлось озадачить форум математиков и после совместного обсуждения проблемы (в теме: «Распределение порядка во всех перестановках») мне (под ником Scholium) удалось вычислить эту величину :
Не правда ли интересно? Случайная последовательность и обладает частичным порядком больше минимального! Что уж тут говорить про реальные данные упорядоченность которых всегда выше абсолютно равномерного распределения случайных величин. Вот почему нас особенно привлекает данный алгоритм.
Перейдем теперь непосредственно к описанию нашего алгоритма.
Описание алгоритма
Он состоит из основных двух операций.
1. Разделение (расщепление) (Split) данной сортируемой последовательности S на множество локально упорядоченных (по возрастанию (не убыванию) или убыванию) подпоследовательностей {S1, S2, S3, . . . , SN}, где все подпоследовательности, кроме, быть может, последней содержат более одной записи (ключа). Упорядоченную подпоследовательность Sn для краткости будем называть УПП Sn.
2. Объединение (слияние) (Merge) смежных пар УПП одного уровня в одну (слева направо или сверху вниз), с учетом порядка упорядочения этих подпоследовательностей. Т.е., убывающая последовательность сливается с "конца", а возрастающая с "начала".
Эти две операции повторяются до тех пор, пока вся последовательность S не будет состоять из одной только подпоследовательности, т.е., пока она не станет упорядоченной.
Пример использования данного алгоритма сортировки показан на рис. 1. Первая строчка это данная (неизменяемая) последовательность, последняя искомая (отсортированная).
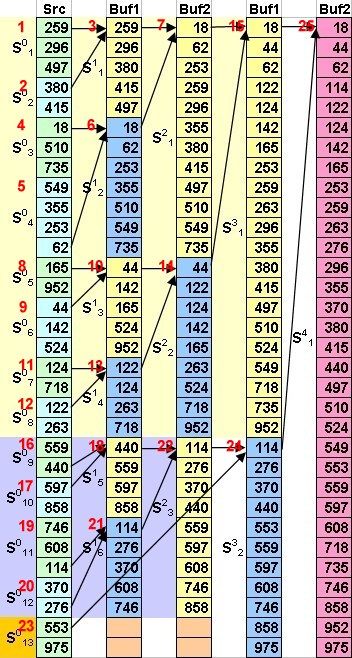
Простой алгоритм внешней сортировки "естественным слиянием"
Дан внешний (файловый) источник УПП S0 и достаточное количество M внешних (файловых) буферов S1, . . . , SM необходимого размера. Источник S0 не должен изменяться, а буфера S1, . . . , SM могут менять свое содержимое. Требуется получить отсортированный источник S0 в некотором буфере, используя попарное слияние упорядоченных подпоследовательностей.
1. Если источник УПП S0 пуст, то конец алгоритма (нет данных).
2. Если источник S0 содержит только одну УПП, то он и будет искомым, с учетом порядка сортировки этой УПП. Конец алгоритма.
3. Если количество УПП источника более одного, тогда S0 попарно (определяется функцией Split) объединяется (функция Merge) в S1, S1 в S2 и т.д., пока в SM не останется одна единственная УПП. Если в текущем Sk (1 <= k < M) имеется не объединенная УПП (при нечетном количестве всех УПП данного уровня k), то она просто копируется в ближайший буфер SK, где также содержится необъединенная УПП, на свое место (K > k), при условии, что k и K имеют разную четность. Затем вновь образовавшаяся пара УПП объединяется. Если же k и K имеют одинаковую четность, т.е. фактически находятся в одном буфере, то они объединяются сразу, без копирования. И так до получения одной единственной конечной УПП. Конец алгоритма.
Оптимизация простого алгоритма
Легко видеть, что число М можно сократить до двух. Кроме этого, последнюю нечетную УПП нет необходимости копировать несколько раз до ее объединения, достаточно делать это не более одного раза. Правда в этом случае может понадобится слияние из двух разных источников (см. рис. 1) в свободный буфер, что немного усложнит функцию Merge. Функцию Split достаточно применять не более одного раза и использовать ее результаты сразу, чтобы не хранить лишние данные.
1. Выделяем текущую смежную пару УПП при проходе по всем искомым записям источника. Данные нечетных УПП сохраняем в нулевом элементе массива структур этих данных.
2. Текущие данные четной УПП объединяем с сохраненными данными предыдущей нечетной УПП с помощью функции Merge в соответствующем буфере.
3. Если в объединяющем буфере данная объединенная УПП нечетная, то сохраняем ее параметры в следующем элементе массива структур данных УПП, иначе (для четной УПП) объединяем ее в другом буфере.
Описание функции Split
Функция Split, которая выполняется только один раз (в один проход), должна определить начало и конец текущей подпоследовательности, ее длину, порядок сортировки (1 для неубывающей подпоследовательности, –1 для убывающей и 0 для УПП состоящей только из одного элемета, замыкающего текущую последовательность данных), а также адресов источников УПП и целевого буфера, параметры, характеризующие собственно данные и т.п.
Чтобы это проделать, достаточно иметь количество данных больше двух, т.е. три и более. Если элементов меньше трех, то они уже образуют одну УПП, параметры которой определяются тривиально. Для большего количества элементов мы определяем начальный порядок, сравнивая первые два элемента. Затем последовательно сравниваем второй и третий, третий и четвертый элементы и так далее, до тех пор, пока их порядок совпадает с начальным. Как только порядок изменился мы сразу же получаем границу очередной УПП, данные о которых уже можно использовать в функции Merge. Для этого информацию о нечетных УПП сохраняем в заданном массиве структур с элементом 0 <= k < M, где M – размерность длинного целого в операционной системе. Для Win32 M = 32.
Далее, поскольку функция Split используется у нас только один раз то мы не будем выделять ее в отдельную функцию, а вот функцию Merge будем.
Описание функции Merge
Здесь мы будем использовать классическую реализацию этой функции, т.е., как уже упоминалось выше, из очередей данных будем последовательно выбирать (с удалением из очереди) максимальное или минимальное значение и записывать его в искомую последовательность.
Функция, которая у нас будет управлять работой Split и Merge мы назовем NaturalMergeSort.
Описание функции NaturalMergeSort
Эта функция состоит из двух основных частей. Первая обрабатывает все четные УПП, по мере их появления, а вторая все оставшиеся нечетные.
Продемонстрируем сказанное на следующих рисунках. Первая часть алгоритма имеет дело с числом УПП являющимся максимальной степенью двойки не превышающем исходное количество этих УПП (рис. 2).
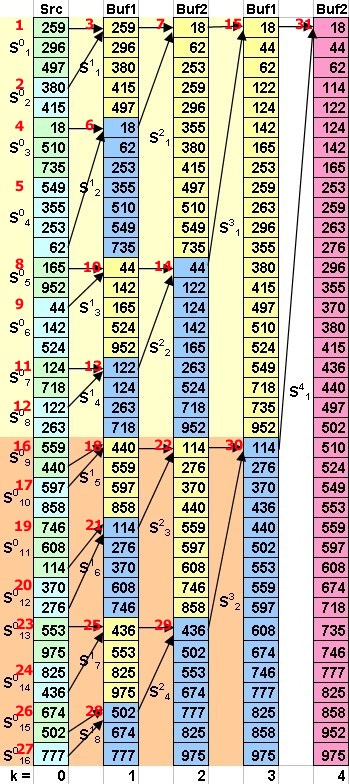
Далее будем считать, что разноцветные прямоугольники содержат различные упорядоченные подопоследовательности данных. Вторая часть алгоритма имеет дело с оставшимися ("зависшими") УПП после выполнения первой части алгоритма (рис. 1). Естественно, если количество УПП равно степени двойки, то вторая часть не понадобится. На рис. 3-7 показана работа второй части алгоритма для различных значений количества УПП.
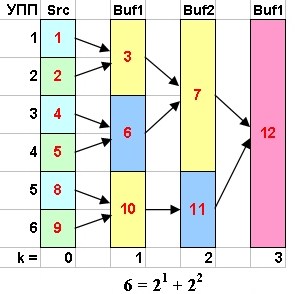
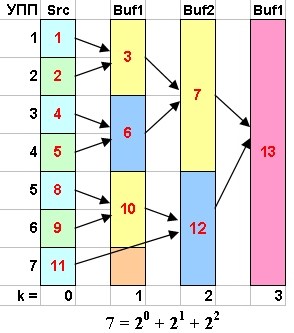
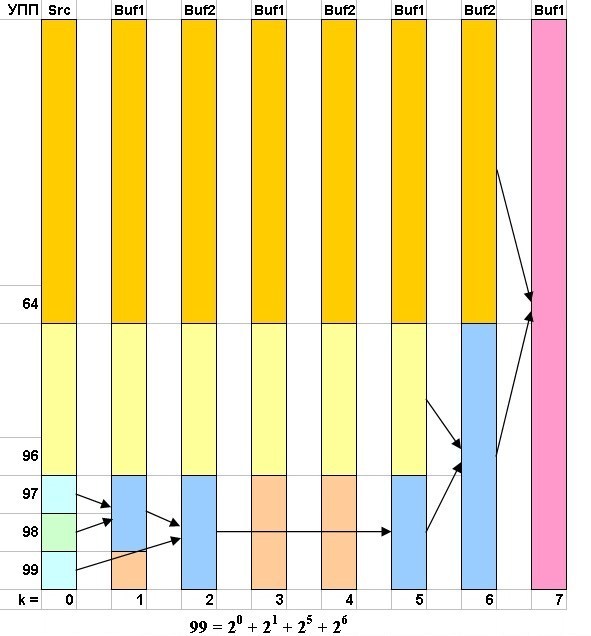
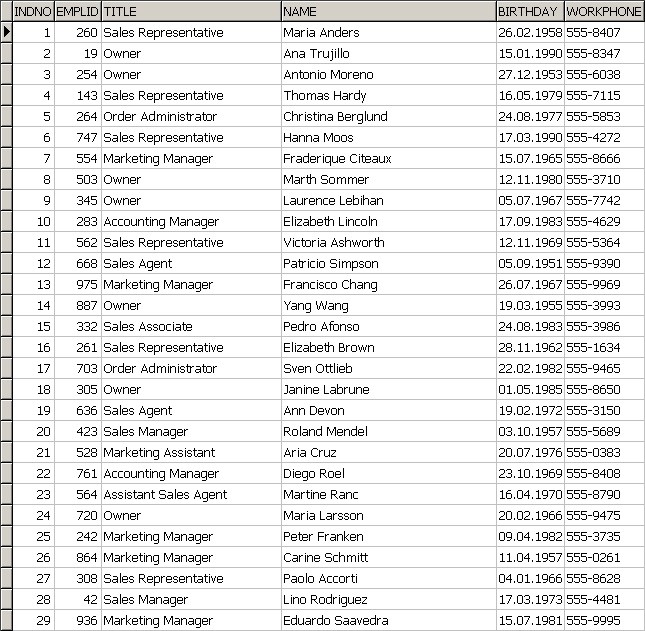
Теперь, когда идея нашего алгоритма ясна можно перейти к его программной реализации. Поскольку мы пишем рабочий вариант программы, то мы будем исследовать реальный источник данных. Для наших будущих целей достаточно если это будет бинарный файл в котором будет присутствовать блок строковых данных (рис. 8).
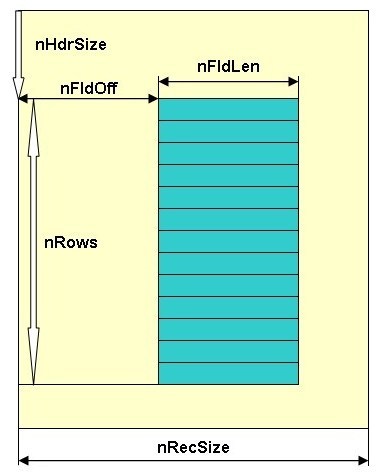
Подобной структурой обладают, например dbf файлы. Поэтому мы предоставим тестовый файл Sort.dbf . Он содержит несколько полей и 360 записей. Вид этого файла показан на рис 9.
Параметры всех полей данных содержатся в структуре g_DataBlock и представлены в тестовой программе. Текущим является поле Name, остальные закомментированы. Конечно, ничто не мешает нам вычислять эти параметры автоматически, но это уже к целям сортировки не относится. Однако эта возможность доступна в программном коде статьи: "Создание и проецирование в память существующих DBF файлов как альтернатива сериализации данных при работе с модифицированными списками CListCtrl в виртуальном режиме на диалогах MDI приложения".
В результате работы программы из заданного поля тестового dbf файла будут извлечены и отсортированы во временном файле соответствующие записи, причем помимо собственно данных будут еще представлены номера позиций (строк или рядов) данного поля данных в текущем блоке данных. Эти номера позиций отсчитываются от нуля. Поскольку номера позиций хранятся в бинарном виде, то кроме этого будет еще запущена тестовая процедура представляющие эти искомые данные в текстовом формате. Оба буферных файла формируются со случайными именами в текущем каталоге, которые будут показаны в соответствующем сообщении (рис. 10). Вообще-то эти временные файлы подлежат дальнейшему удалению, но мы оставляем их для демонстрационных целей.
Для нашего удобства мы используем технологию Memory Mapped Files (MMF) в функции SortFileDataBlock, т.е. файлов отображенных в память. Хотя это в данном случае совершенно не принципиально и легко может быть убрано, путем незначительного усложнения кода. Однако в силу перспективности и удобства MMF мы оставляем ее для демонстрационных целей.
Теперь можно непосредственно перейти к коду основной функции сортировки естественным слиянием с неубывающими и убывающими упорядоченными подпоследовательностями.
Код основной функции функции NaturalMergeSort
////////////////////////////////////////////////////////////////////////
// NaturalMergeSort
////////////////////////////////////////////////////////////////////////
BOOL NaturalMergeSort(NMS *pNms) {
//*** Natural Merge Sort structure
TCHAR *szFileBuf1 = pNms->szFileBuf1; // Name of first file
// buffer
TCHAR *szFileBuf2 = pNms->szFileBuf2; // Name of second file
// buffer
HANDLE hSrcFile = pNms->hSrcFile; // Handle of data source file
HANDLE hFileBuf1 = pNms->hFileBuf1; // Handle of first temporary
// file buffer
HANDLE hFileBuf2 = pNms->hFileBuf2; // Handle of second temporary
// file buffer
BYTE *pSrcFile = pNms->pSrcFile; // Maps view of data source file
BYTE *pFileBufView1 = pNms->pFileBufView1; // Maps view of first file
// buffer
BYTE *pFileBufView2 = pNms->pFileBufView2; // Maps view of second
// file buffer
//*** String data block structure
ULONG nHdrSize = g_DataBlock.nHdrSize; // Header size of data source
ULONG nRecSize = g_DataBlock.nRecSize; // Record size of data source
UINT nFldOff = g_DataBlock.nFldOff; // Offset of data field in record
// of source
UINT nFldLen = g_DataBlock.nFldLen; // Length of data field
ULONG nRows = g_DataBlock.nRows; // Rows count of data source
HANDLE hOut = NULL; // Handle of destination file buffer of OSS
BYTE *pOut = NULL; // Pointer of destination file buffer of OSS
OSS Oss = {0}; // OSS`s structure
DWORD nRecNo = 0; // Reading "buffer" of record number
DWORD dwBytes = 0; // Number of written bytes
ULONG nLineInd = 0;
ULONG nRow = 0;
//*** Sorts ordered subsequences (OSS)
if(nRows > 2) {
int j = 0;
ULONG nNextRow = 0;
ULONG nOldNextRow = 0;
ULONG nInRow = 0;
ULONG nOldRow = 0;
ULONG nOldRows = 0;
int nOldSortSign = 0;
int nLastSortSign = 0;
ULONG nOutRow = 0;
ULONG nOldOutRow = 0;
ULONG nOSS = 0; // Number of OSS
ULONG nOSSBegin = 0; // Begin of OSS
ULONG nOSSEnd = 0; // End of OSS
ULONG nOSSRows = 0; // Rows count of OSS
int nSortSign1 = 0; // Sign of sorting of first OSS of source
int nSortSign2 = 0; // Sign of sorting of second OSS of source
CString *psFldVal1 = NULL;
CString *psFldVal2 = NULL;
BOOL bFirstRec = TRUE;
INROWS aInRows[32] = {0}; // Array of INROWS`s structures for OSS
Oss.nFldLen = nFldLen;
//*** Merges even couples of ordered subsequences (OSS)
for(nRow = 0; nRow <= nRows; nRow++) {
nLineInd = nRow*nRecSize + nFldOff;
try {
if(nRow < nRows) {
//*** Copies (nRow, nCol) field value of length nFldLen
// We do this as it hasn`t NULL terminator
if(bFirstRec) {
psFldVal1 = new CString((LPCSTR) &pSrcFile[nLineInd],
nFldLen);
bFirstRec = FALSE;
continue;
} else {
psFldVal2 = new CString((LPCSTR) &pSrcFile[nLineInd],
nFldLen);
}
//*** Formates date string into German style
/*
if(m_pDoc->m_acFldType[nCol] == 68) { // = 0x44 ("D") - Date
CString sDate =
sFldVal.Right(2) + _T(".") +
sFldVal.Mid(4, 2) + _T(".") +
sFldVal.Left(4);
sFldVal = sDate;
}
*/
//*** Compares two strings
if(!Compare(psFldVal1, psFldVal2, &nSortSign2)) {
//_M("CreateIndexFile : Error Compare!");
return FALSE;
}
} else
nOSS = nOSS;
//*** Defines the end of ordered subsequence (OSS)
if((nSortSign1 != 0 && nSortSign1 != nSortSign2)
|| nRow == nRows) {
nOSS++; // The number of ordered subsequences (OSS)
nOSSEnd = nRow - 1; // The end of OSS
nOSSRows = nOSSEnd - nOSSBegin + 1; // The len of OSS
nLastSortSign = nSortSign1;
nInRow = (nSortSign1 == 1) ? nOSSBegin : nOSSEnd;
if(nOSS%2) { // Odd OSS
//*** Saves odd OSS parameters
aInRows[0].nInRow = nInRow;
aInRows[0].nInRows = nOSSRows;
nOldSortSign = nSortSign1;
} else { // Even OSS
// log(nOSS)/log(2) < 32
for(j = 0; j <= (int)(log(nOSS)/log(2)); j++) {
// nOSS % 2^(j+1) = 0
if(nOSS % (ULONG) pow(2, j+1) == 0) {
nOutRow = (nOSS == pow(2, j+1)) ? 0 : nOutRow;
if(j == 0) {
Oss.hIn1 = NULL;
Oss.pIn1 = pSrcFile;
Oss.nRecSize1 = nRecSize;
Oss.nRecSize2 = nRecSize;
Oss.nFldOff1 = nFldOff;
Oss.nFldOff2 = nFldOff;
//Oss.nFldLen = nFldLen;
} else {
Oss.hIn1 = (j%2 == 0) ? hFileBuf2 : hFileBuf1;
Oss.pIn1 = (j%2 == 0) ? pFileBufView2 : pFileBufView1;
Oss.nRecSize1 = nFldLen + sizeof(nRecNo);
Oss.nRecSize2 = Oss.nRecSize1;
Oss.nFldOff1 = 0;
Oss.nFldOff2 = 0;
//Oss.nFldLen = nFldLen + sizeof(nRecNo);
}
//Oss.nFldLen = nFldLen;
Oss.hIn2 = Oss.hIn1;
Oss.pIn2 = Oss.pIn1;
Oss.hOut = (j%2 == 0) ? hFileBuf1 : hFileBuf2;
Oss.pOut = (j%2 == 0) ? pFileBufView1 : pFileBufView2;
nInRow = (j > 0) ? nOldRow : nInRow;
nSortSign1 = (j > 0) ? 1 : nSortSign1;
nOldSortSign = (j > 0) ? 1 : nOldSortSign;
nOutRow = (j > 0) ? nInRow : nOutRow;
nOldOutRow = nOutRow;
Oss.nInRow1 = aInRows[j].nInRow;
Oss.nInRow2 = nInRow;
Oss.nInRows1 = aInRows[j].nInRows;
Oss.nInRows2 = (j > 0) ? nOldRows : nOSSRows;
Oss.nInSS1 = nOldSortSign;
Oss.nInSS2 = nSortSign1;
Oss.nOutRow = nOutRow;
//*** Merges two OSS into one
if(!Merge(&Oss)) { // Pointer to OSS structure
//_M("CreateIndexFile : Error of merger of two OSS!");
return FALSE;
}
nOutRow = Oss.nOutRow;
//*** Saves even OSS parameters
nOldRow = aInRows[j+1].nInRow;
nOldRows = aInRows[j+1].nInRows;
nOldSortSign = nSortSign1;
aInRows[j+1].nInRow = nOldOutRow;
//aInRows[j+1].nInRows = aInRows[j].nInRows + nOSSRows;
aInRows[j+1].nInRows = Oss.nInRows1 + Oss.nInRows2;
nSortSign1 = 1;
}
}
}
nOSSBegin = nRow; // The begin of ordered subsequences (OSS)
nSortSign1 = 0;
} else
nSortSign1 = nSortSign2;
psFldVal1 = psFldVal2;
} catch(...) {
_M("CreateIndexFile : Error exception!");
//*** Forces to exit from the application as else will be a lot
// messages
exit(-1);
}
}
//*** Handle of destination file buffer of OSS
hOut = (nOSS == 1) ? NULL : (nOSS%2 == 0) ? hFileBuf1 : hFileBuf2;
//*** Pointer of destination file buffer of OSS
pOut = (nOSS == 1) ? pSrcFile : (nOSS%2 == 0) ? pFileBufView1 :
pFileBufView2;
//*** Merges the rest (odd couples) of ordered subsequences (OSS)
if(nOSS > pow(2, --j)) { // nOSS != 2^j && nOSS > 2
//*** As minimum two natural numbers exist so that
// nOSS = 2^n1 + 2^n2 (n1 < n2)
int n1 = 0;
int n2 = 0;
Oss.nInRow1 = 0;
Oss.nInRows1 = 0;
//j = 0;
//*** Finds n1
int i = 0;
nOldRow = 0;
nOldRows = 0;
ULONG nOSS1 = nOSS;
while(nOSS1 % 2 == 0) {
nOSS1 /= 2;
i++;
}
n1 = i; // Must be n1 >= 0!
ULONG nOSS0 = nOSS - (ULONG) pow(2, n1);
ULONG nOSS2 = 0;
//while(nOSS > (ULONG) pow(2, n1) && j++ < 32) { // For Win32
while(nOSS > (ULONG) pow(2, n1)) {
//*** Finds n2
i = 0;
nOSS2 = nOSS0;
while(nOSS2 % 2 == 0) {
nOSS2 /= 2;
i++;
}
n2 = i; // Must be n2 > 0 as n2 > n1 >= 0!
Oss.hIn1 = (n1 == 0) ? NULL : (n1%2 == 0) ? hFileBuf2 :
hFileBuf1;
Oss.pIn1 = (n1 == 0) ? pSrcFile : (n1%2 == 0) ? pFileBufView2 :
pFileBufView1;
Oss.hIn2 = (n2%2 == 0) ? hFileBuf2 : hFileBuf1;
Oss.pIn2 = (n2%2 == 0) ? pFileBufView2 : pFileBufView1;
Oss.hOut = (n2%2 == 0) ? hFileBuf1 : hFileBuf2;
Oss.pOut = (n2%2 == 0) ? pFileBufView1 : pFileBufView2;
ULONG nRecSize = nFldLen + sizeof(nRecNo);
//*** g_DataBlock.nRecSize - Record size of data source
Oss.nRecSize1 = (n1 == 0) ? g_DataBlock.nRecSize : nRecSize;
Oss.nRecSize2 = nRecSize;
Oss.nFldOff1 = (n1 == 0) ? nFldOff : 0;
Oss.nFldOff2 = 0;
//*** Checks evenness n1 and n2
if(Oss.pOut == Oss.pIn1) {
ULONG nOff = (n1 < n2) ? aInRows[n1].nInRow : nOldRow;
nOff *= nRecSize;
ULONG nSize = (n1 < n2) ? aInRows[n1].nInRows : nOldRows;
nSize *= nRecSize;
//*** Simply copies OSS from pIn1 into pIn2
CopyMemory(
Oss.pIn2 + nOff, // Pointer to address of copy destination
Oss.pIn1 + nOff, // Pointer to address of block to copy
nSize // Size, in bytes, of block to copy
);
Oss.hIn1 = Oss.hIn2;
Oss.pIn1 = Oss.pIn2;
}
Oss.nInRow1 = aInRows[n1].nInRow;
Oss.nInRow2 = (n1 < n2) ? aInRows[n2].nInRow : nOldRow;
Oss.nInRows1 = aInRows[n1].nInRows;
Oss.nInRows2 = (n1 < n2) ? aInRows[n2].nInRows : nOldRows;
Oss.nInSS1 = (n1 > 0) ? 1 : nLastSortSign;
Oss.nInSS2 = 1;
Oss.nOutRow = Oss.nInRow2;
//*** Merges two OSS into one
if(!Merge(&Oss)) { // Pointer to OSS structure
//_M("CreateIndexFile : Error of merger of two OSS!");
return FALSE;
}
n1 = n2 + 1;
//*** Saves old aInRows[n1] structure
nOldRow = aInRows[n1].nInRow;
nOldRows = aInRows[n1].nInRows;
//*** Changes aInRows[n1] structure
aInRows[n1].nInRow = Oss.nInRow2;
aInRows[n1].nInRows = Oss.nInRows1 + Oss.nInRows2;
nOSS0 = nOSS0 - (ULONG) pow(2, n2);
}
}
}
//*** TEST
//*
BYTE acCRLF[2] = {13, 10};
HANDLE hIn = Oss.hOut; // Handle of source file buffer of index data
if(hIn) { // nOSS > 1
//*** Handle of destination file buffer of index data
HANDLE hOut = (hIn == hFileBuf1) ? hFileBuf2 : hFileBuf1;
//*** Moves file pointer of current file buffer
if(SetFilePointer(hIn, 0, NULL, FILE_BEGIN) == (DWORD) -1) {
_M("CMainDoc:CreateIndexFile : Failed to call SetFilePointer
function!");
return FALSE;
}
//*** Moves file pointer of current file buffer
if(SetFilePointer(hOut, 0, NULL, FILE_BEGIN) == (DWORD) -1) {
_M("CMainDoc:CreateIndexFile : Failed to call SetFilePointer
function!");
return FALSE;
}
//*** Merges even couples of ordered subsequences (OSS)
for(ULONG i = 0; i < nRows; i++) {
BYTE *acStr = new BYTE[nFldLen]; // Reading buffer of field data
char acNo[2*sizeof(ULONG)]; // Writing buffer of record number
//*** Reads pcStr into first temporary file buffer
if(!ReadFile(hIn, acStr, nFldLen, &dwBytes, NULL)) {
_M("NaturalMergeSort : Failed to call ReadFile function for
acStr!");
return FALSE;
}
//*** Reads nRecNo into current temporary file buffer
if(!ReadFile(hIn, &nRecNo, sizeof(nRecNo), &dwBytes, NULL)) {
_M("NaturalMergeSort : Failed to call ReadFile function for
&nRecNo!");
return FALSE;
}
//*** Writes pcStr into first temporary file buffer
if(!WriteFile(hOut, acStr, nFldLen, &dwBytes, NULL)) {
_M("NaturalMergeSort : Failed to call WriteFile function for
acStr!");
return FALSE;
}
//*** Converts DWORD to char array
sprintf(acNo, "%8d", nRecNo); // 8 = 2*sizeof(ULONG)
//*** Writes pcStr into first temporary file buffer
if(!WriteFile(hOut, acNo, sizeof(acNo), &dwBytes, NULL)) {
_M("NaturalMergeSort : Failed to call WriteFile function for
acNo!");
return FALSE;
}
//*** Writes pcStr into first temporary file buffer
if(!WriteFile(hOut, acCRLF, sizeof(acCRLF), &dwBytes, NULL)) {
_M("NaturalMergeSort : Failed to call WriteFile function for
acCRLF!");
return FALSE;
}
}
} else { // nOSS == 1
hOut = hFileBuf1; // Handle of destination file buffer of index
// data;
char acNo[2*sizeof(ULONG)]; // Writing buffer of record number
for(nRow = 0; nRow < nRows; nRow++) {
nLineInd = nRow*nRecSize + nFldOff;
//*** Writes pcStr into first temporary file buffer
if(!WriteFile(hOut, &pSrcFile[nLineInd], nFldLen, &dwBytes,
NULL)) {
_M("NaturalMergeSort : Failed to call WriteFile function for
&pSrcFile[nLineInd]!");
return FALSE;
}
//*** Converts DWORD to char array
sprintf(acNo, "%8d", nRow); // 8 = 2*sizeof(ULONG)
//*** Writes pcStr into first temporary file buffer
if(!WriteFile(hOut, acNo, sizeof(acNo), &dwBytes, NULL)) {
_M("NaturalMergeSort : Failed to call WriteFile function for
nRow!");
return FALSE;
}
//*** Writes pcStr into first temporary file buffer
if(!WriteFile(hOut, acCRLF, sizeof(acCRLF), &dwBytes, NULL)) {
_M("NaturalMergeSort : Failed to call WriteFile function for
acCRLF!");
return FALSE;
}
}
}
//*
//*** TEST
sprintf(
g_szStr,
_T("NaturalMergeSort : See out files: `%s` and `%s`!"),
szFileBuf1,
szFileBuf2
);
_M(g_szStr);
return TRUE;
} // NaturalMergeSort
Заметим, что при попытке сортировки первого блока данных (поля IndNo), которое уже отсортировано, наша функция NaturalMergeSort определит, что в данном случае мы имеем всего одну единственную УПП и ничего сортировать не надо, и для вывода результатов будет использоваться непосредственно источник, а не буферный файл.